Indexing
Categories of indexing
Dense Indexing
- All keys will be mapped to a certain block on the disk.
- Problem is this index table itself might be huge depending on the number of rows we have.
Sparse indexing
- Table data must be sorted the column where we are indexing.
Types of indexing
Primary
Created on the ordered primary key of a table. Use preferably Sparse indexing.
Clustered
Created on the ordered non-key field of the table. Use preferably Sparse indexing.
Secondary
Created on the unordered primary key of the table. Here only dense index is possible because the table is not ordered.
How is Indexing achieved
B trees
- B tree or B+ tree are used to quickly locate the data.
- They are self-balancing binary trees. It is used to store the data in a sorted manner.
- B+ trees store the actual data in only the final leaf nodes, while B tree stores data in the intermediate layers too.
Log Strusctured Merge Tree (LSM)
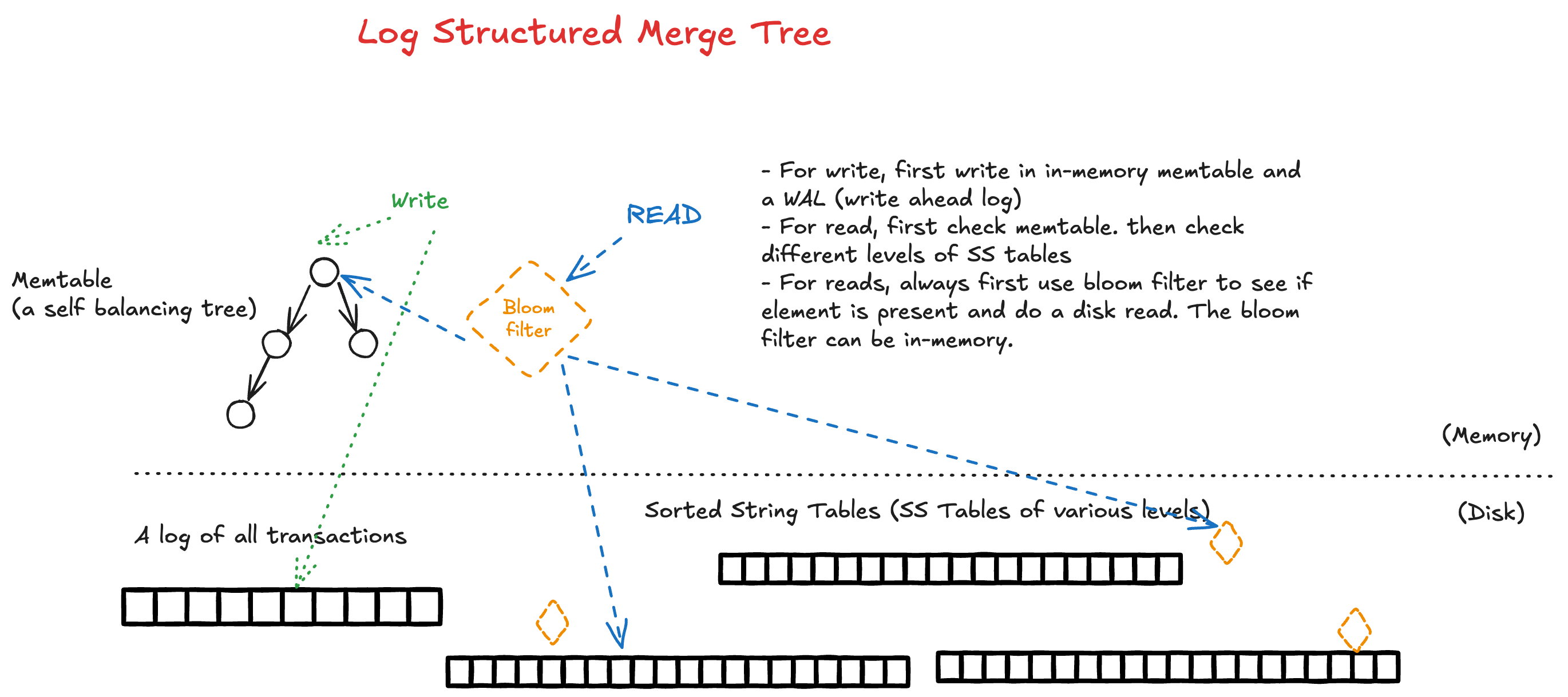
An LSM tree organizes data into a hierarchy of components, leveraging both memory and disk storage to handle data efficiently.
- Memtable (In-Memory Component) New data (inserts, updates, and deletes) is first written to an in-memory, write-ahead log (WAL) for durability and then inserted into a memory-resident sorted data structure, often a SkipList or an AVL tree, called the memtable. This allows for very fast, low-latency writes.
- SSTables (On-Disk Components): When the memtable reaches a predefined size, it is flushed to disk as an immutable Sorted String Table (SSTable) file. This process is a fast, sequential I/O operation. The on-disk data is organized into multiple levels (L0, L1, etc.), each containing SSTables.
- Compaction and Merging: A background process called “compaction” periodically merges multiple smaller SSTables from one level into larger ones in the next level. This process is similar to merge sort and is crucial for:
- Removing obsolete or deleted entries (marked with a “tombstone” in newer SSTables).
- Reclaiming disk space.
- Maintaining sorted order within and across levels to optimize read performance.
Indexing and Query Performance
- Writes: Writes are highly efficient due to in-memory buffering and sequential disk appends, making LSM trees ideal for high-ingestion rate scenarios like logging and time-series data.
- Reads: Reads are more complex than in B-trees because a key might exist in the memtable, multiple SSTables, or have a tombstone marking it as deleted. The system checks the newest components first (memtable, then L0, L1, etc.). To optimize this, LSM trees often use:
- Bloom filters to quickly check if a key is likely present in an SSTable, avoiding unnecessary disk reads.
- Sparse indexes stored in memory, which map key ranges to physical locations within SSTable files.
Used in
- NoSQL systems like Cassandra, RocksDB, and HBase
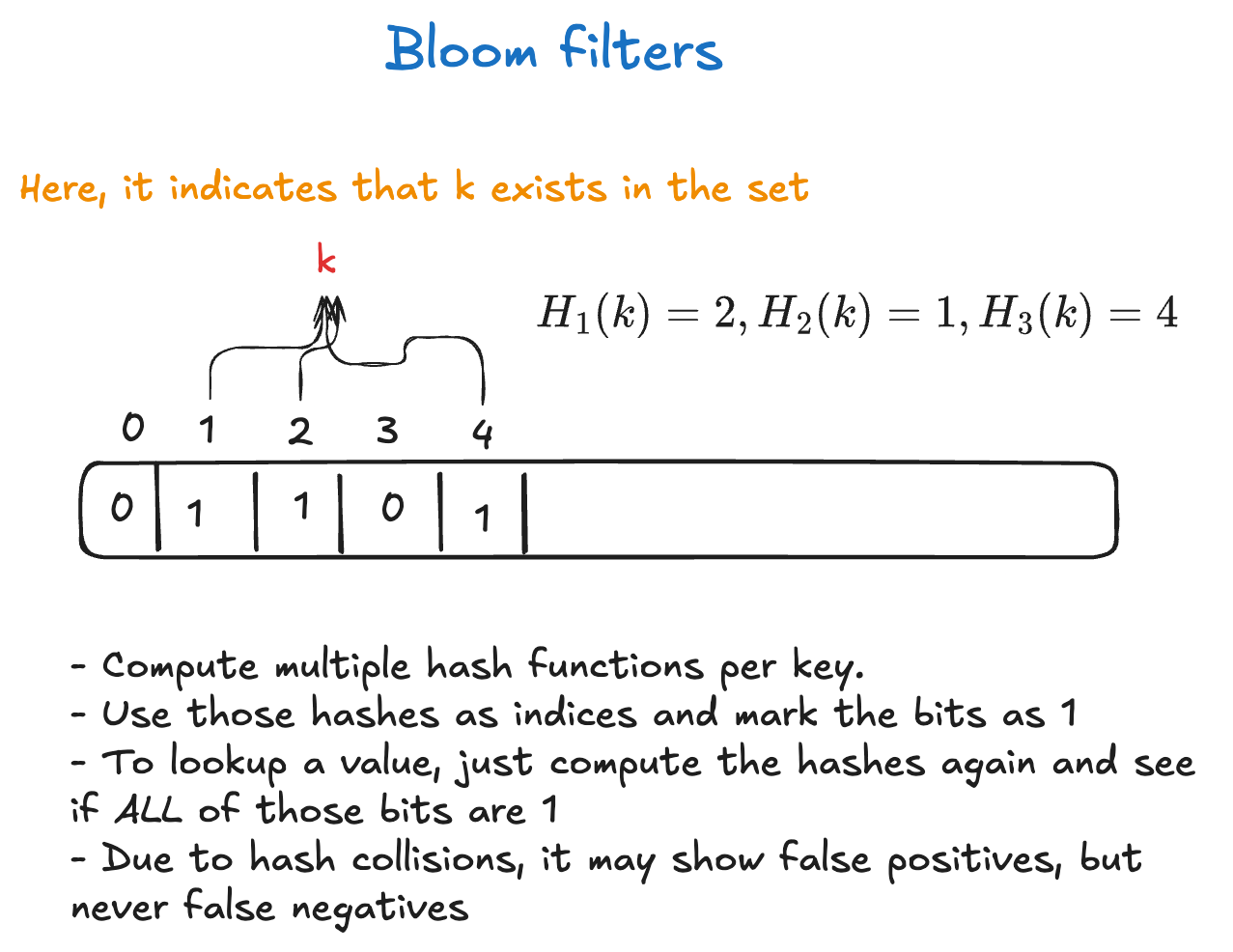
Bloom filters